Trees - Euler Tours
Euler Tour
We mostly divide our problems into mostly two types: Array problems and Tree/Graph problems.
But what if we can convert some specific type of tree problems into actually array problems?
Problem: We are given a Tree. We have to perform two types of operations:
- Query: Find the sum of weights of all nodes in the subtree of the given query node.
- Update: Set the weight of a given node to X.
Obvious Solution? For each update just make the corresponding weight of the given node to X. For Queries, traverse the whole subtree and find the sum. This has a worst case of O(N*Q).
However we will come up with a O(nlogn) solution to this same problem by the end of this post.
Start Time/End Time
When we do a DFS, suppose we keep a global variable called time.Whenever we visit a new node, we are doing something new and thus we "increase" the time. This can be thought of as a time variable that we are manually keeping track of. NOT the system time. So some points that are clear are that time always increases. Moreover, we cannot do 2 things at the same time. Thus, when we visit a new node, we increase the time counter. But when we backtrack, we dont do that.
In all this my point is that, if we keep track of the FIRST "time" that we visit a node (I am considering backtracking as also visiting the node) then it is easy to see that they will be distinct. This is what we call the "start" time of a node. Similarly, we say "end" time to be the last time that we visit that node. (this is why we consider it visiting a node EVEN when backtracking)
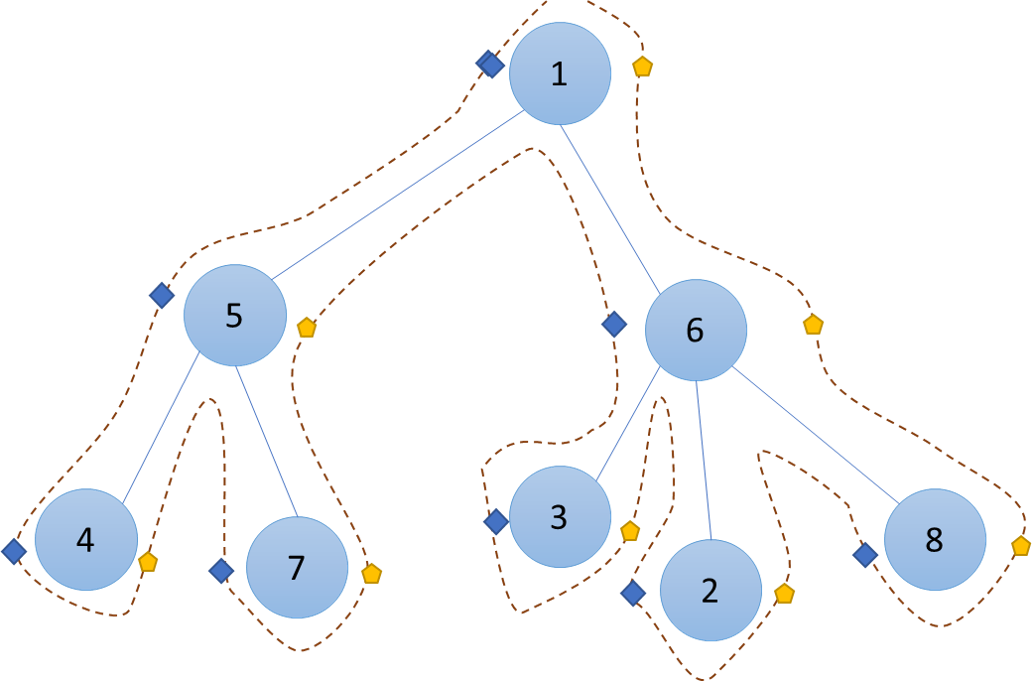
So to make it a bit more clear, let me give a dry run for the DFS-start time end time of the above tree.
- We start at node 1. start[1] = 1.
- We go to node 5. start[5] = 2.
- We go to node 4. start[4] = 3
- Since we have no children left, we backtrack. However, this will also be the last time I am visiting the node 4, therefore end[4] = 3. Moreover, we dont increment the TimeCounter this time because we are backtracking.
- We backtrack to node 5. Time is still 3.
- We go to node 7. Note that since we are now visiting a new node, time is updated. thus, start[7] = 4
- Same logic as node4. Thus end[7] = 4
- We backtrack to node 5. Time is not updated. However this is the last time we are visting node 5, thus end[5] = 4
- We back track to node 1. Time is not updated.
- We go to node 6. Since its a new node, time is updated. Thus start[6] = 5.
- And so on.... (I hope you get the idea)
Now if we notice the values,
| Node | Start time | End time |
| 1 | 1 | 8 |
| 2 | 7 | 7 |
| 3 | 6 | 6 |
| 4 | 3 | 3 |
| 5 | 2 | 4 |
| 6 | 5 | 8 |
| 7 | 4 | 4 |
| 8 | 8 | 8 |
Observe that ALL the start values are unique, just as we had claimed. However, the end times are not distinct. But the question is, so what if these values are unique? How does it matter to us?
So first observe that not only are the start times unique, they also lie between 1 and N where N is the number of nodes. This is because we updated out TimeCounter only when visting new nodes and since there are only atmost N nodes, TimeCounter is always less than or equal to N.
Now the magic part: from this data, we can create an array where the index number are the start time and the value in that index is the corresponding node which had that start time.
So this array, which we often called the euler array of the tree will look something like this:
| index: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Node: | 1 | 5 | 4 | 7 | 6 | 3 | 2 | 8 |
What we did here is simple: we put the elements in the array in order of their start times.
This array is also analogous to if we had added to the array each time we visited the new node, the ID number of the node. We would have basically gotten the same array.
Now what to do with the End time? How are those values useful to us? Let's see.
Consider the node 6 in our example. It has a start time of 5, end time of 8. As expected, in our euler array, the value of index 5 is 6. Now, consider the subarray from indices 5 to 8. The nodes in that region are 6,3,2,8. However, isn't that EXACTLY the nodes that were there in the subtree of node 6 in our tree? (You can see this is true for any start time/end time pair you take.)
So how does this black magic work? Well, in our algorithm, see that start time was the first time we visited the node and end time is the last time we visited the node. Now, observe that the start (and end) time of ALL the nodes in the subtree lie within the start and end time of our node. This is because, they have to be bigger than start time of our node, because that is the first time that we are entering this node's subtree. Again, they all have to be lesser than or equal to the end time because that's the time when we leave this node to go to the ancestor and thus we will never come back to this path again.
If you are still confused about this, as is natural, reread and go through the example again. Try making your own tree and see if this works on the example that you have taken.
Usefulness?
What we have done till now, is that given any node in the tree, if we know it's start time and end time, we can get all of the nodes in the subtree of our node by going over the subarray given by the start and end time of our node.
So basically, a node's subtree is now represented by a range in our array. And this turns out to be a HUGE advantage in a wide variety of problems. It is much easier to handle arrays than a tree and this is why this "linearization" of our tree into an array is very useful.
So let's again see our original problem:
- Query is now transformed to getting the range sum in our array since the subtree of the node is just a range in the array
- update is just setting the value of a position in the array to some specific value.
But this is our ordinary range sum with update problem which can be easily solved with a BIT or Segment Tree.
Complexity
Creating this euler array, and the start times and end times is just a DFS, and so O(n) time and memory. Normally we use a segment tree on this array which makes the overall complexity O(nlogn)
Pseudocode:

Going Further
Sometimes, if we just store the occurance of a node in the euler array only at the start time, it is not sufficient. We may need to store in the array the node twice: once at the time when we enter the node and when we leave it. Or maybe we may need to print it to the euler array EACH time that we visit a node and not just at the start or end time. Well, the former can be achieved if we just update the TimeCounter at the time of backtracking too. Again, you can easily confirm that all values of start time AND end time in this case are distinct and so can be written to the array. Again complexity is O(n) as each node can be written to the array atmost twice and overall we do only 1 DFS. If we want to write each time we visit a node, we just need to update the TimeCounter during each DFS call to its children too. The time complexity is STILL O(N). Proof is something like, each node can be written at most its degree*2 times. Sum of all degree of nodes in a tree is O(N) and so this is still O(N).
However in these cases, notice that in the subarray [ start time to end time ] of our euler array, we may have duplicates of each node. In fact, we have atleast two occurances of each node.
Normally we use our normal variation: write the occurances only at start time. But problems like finding LCA of 2 nodes in a tree requires the second version.
Euler tours help in efficiently traversing trees for various queries. To automate Firefox browser actions smoothly, you can use Geckodriver with Selenium Java for seamless control.
ReplyDelete